Index types
Covering Index Type
In Hyperspace, “covering” index means its index data contains actual source data, so we could alternatively read from the index data when it is applicable. It could be whole or partial data, but the data is rearranged as a different data layout to accelerate some types of Spark queries.
As of v0.6, Hyperspace supports the following two covering indexes:
- (Bucketed) Covering Index
- Z-order Covering Index (since v0.6)
Covering Index
Covering Index is the first type that Hyperspace supports. It can accelerate join queries and filter queries.
Index data layout
The index data consists of indexed columns and included columns, and it is stored as bucketed and
sorted within each bucket by indexed columns. “Bucketed” stands for “hash partitioned” simply;
all rows with the same hash value go into the same bucket.
We use 200 buckets by default which is the default value of spark.sql.shuffle.partitions config
to increase the possibility of index application.
The bucket number for index data is configurable via spark.hyperspace.index.numBuckets.
For example, assume the source data is stored in 1000 files in random order. At index creation time, Hyperspace performs shuffling and sorting by the indexed columns before storing index data. As a result, the index data consists of 200 files (bucket number) by default and within each bucket, rows are sorted by the indexed columns.
Applicable queries
Sort Merge Join
Sort merge join is a well known expensive operation in Spark because it requires full shuffling of both left and right dataset. We can optimize the time for shuffling and sorting datasets, as we already did the required data rearrangement at index creation time; by reading the index data instead of source data, Spark will skip shuffling & sorting for the join. Therefore, if some dataset is repeatedly used for Sort merge joins causing shuffles for every query time, creating a Covering Index would be helpful. We also support mutable dataset for covering index types.
Filter conditions for the first indexed column
Queries including filter conditions for the first indexed column can also be accelerated, since the index data is also sorted within each bucket. Thanks to statistics and data skipping features of Parquet format, the queries can be accelerated by skipping unnecessary row groups while reading the data. It could be less effective compared to global sorting, and only applicable for the first indexed column.
Index creation API
CoveringIndexConfig
To create a Covering Index, CoveringIndexConfig should be used at index creation with:
- index name: name of index; should be unique within an index system directory.
- indexed columns: columns to use for shuffling and sorting.
- included columns: columns to include in the index data.
Scala
import com.microsoft.hyperspace._
import com.microsoft.hyperspace.index.covering._
val df = spark.read.parquet("<path/to/data>")
val idxConfig = CoveringIndexConfig(
"<indexName>",
Seq("<indexedCol1>", "<indexedCol2>"),
Seq("<includedCol1>"))
val hs = new Hyperspace(sparkSession)
hs.createIndex(df, idxConfig)
Python
from hyperspace import Hyperspace
from hyperspace import CoveringIndexConfig
hs = Hyperspace(sparkSession)
idxConfig = CoveringIndexConfig('<indexName>', ['<indexedCol1>', '<indexedCol2>'], ['<includedCol1>'])
df = spark.read.parquet("<path/to/data>")
hs.createIndex(df, idxConfig)
Index Specific configs
spark.hyperspace.index.numBuckets
Z-order Covering Index
Z-order Covering Index type is available since v0.6. It is kind of sorted data, but multiple columns can contribute the order which results in similar values could be collocated.
Index data layout
ZOrderCoveringIndex data is generated by the following:
sourceData
.withColumn("_zaddr", "<zaddress_calculcation>")
.repartitionByRange(numPartitions, col("_zaddr"))
.sortWithinPartitions("_zaddr")
.drop("_zaddr")
numPartitions is determined based on spark.hyperspace.index.zorder.targetSourceBytesPerPartition.
So there will be numPartitions number of files that sorted by Z-address of indexed columns.
If there is only one indexed column, we just sort the data by the column without calculating Z-address.
Applicable queries
Filter conditions for indexed columns
Queries including filter conditions for any of indexed columns can also be accelerated, as the index data is sorted by Z-address of indexed column values. Improvement of query performance is not always guaranteed and depending on the quality of Z-ordered dataset. For example, if the source data is already sorted by a column, then Z-ordering the dataset may deteriorate the query performance with a filter condition of the sorting column. For more information, see below Min/Max data layout analysis utility.
Index creation API
To create a Z-order Covering Index, ZOrderCoveringIndexConfig should be used at index creation with:
- index name: name of index; should be unique within an index system directory.
- indexed columns: columns to use for Z-ordering.
- included columns: columns to include in the index data.
Scala
import com.microsoft.hyperspace._
import com.microsoft.hyperspace.index.zordercovering._
val df = spark.read.parquet("<path/to/data>")
val idxConfig = ZOrderCoveringIndexConfig(
"<indexName>",
Seq("<indexedCol1>", "<indexedCol2>"),
Seq("<includedCol1>"))
val hs = new Hyperspace(sparkSession)
hs.createIndex(df, idxConfig)
Python
from hyperspace import Hyperspace
from hyperspace import ZOrderCoveringIndexConfig
hs = Hyperspace(sparkSession)
idxConfig = ZOrderCoveringIndexConfig('<indexName>', ['<indexedCol1>', '<indexedCol2>'], ['<includedCol1>'])
df = spark.read.parquet("<path/to/data>")
hs.createIndex(df, idxConfig)
Index Specific configs
spark.hyperspace.index.zorder.targetSourceBytesPerPartitionspark.hyperspace.index.zorder.quantile.enabledspark.hyperspace.index.zorder.quantile.relativeError
Min/Max data layout analysis utility for Z-ordering
Z-ordering result might differ based on various factors like data type, value distribution and also other Z-ordering columns; it is hard to expect that the Z-ordered data is effective or not. That is the reason why we introduce the analysis functionality for Z-ordering. It only works for numeric types for now.
Note that it collect the min/max values of each file using spark jobs and generate the result based on them.
Result format
The function provides html and text format to show the result.
HTML format
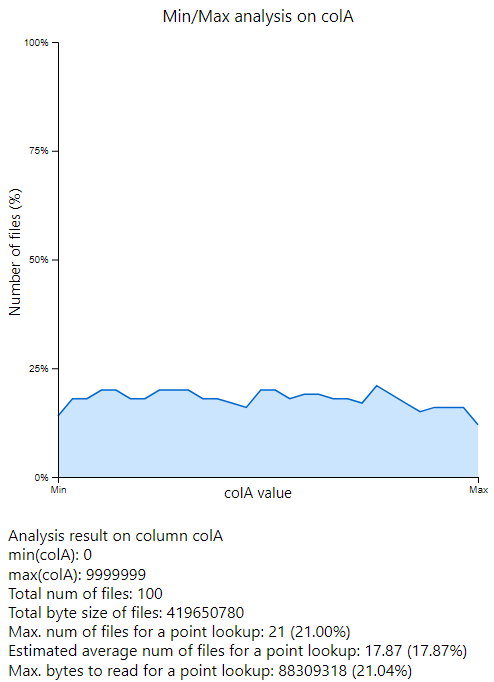
Text format
Min/Max analysis on colA
< Number of files (%) >
+--------------------------------------------------+
100% | |
| |
| |
| |
75% | |
| |
| |
| |
| |
50% | |
| |
| |
| |
| |
25% | |
| *** |
| *************************************** ***** |
|**************************************************|
|**************************************************|
0% |**************************************************|
+--------------------------------------------------+
Min <----- colA value -----> Max
min(colA): 0
max(colA): 9999999
Total num of files: 100
Total byte size of files: 419650780
Max. num of files for a point lookup: 21 (21.00%)
Estimated average num of files for a point lookup: 17.76 (17.76%)
Max. bytes to read for a point lookup: 88309318 (21.04%)
How to interpret
- X-axis: it represents the range group of the column values.
- Y-axis: the percentage of number of files to look up a value based on the minimum and maximum value of each file. So lower percentage means better distribution as we could skip more files. To be more specific, it represents the maximum percentage within each range.
- min(colA): the minimum value of the column in the given dataset.
- max(colA): the maximum value of the column in the given dataset.
- Total num of files: total number of files in the given dataset.
- Total byte size of files: summation of file size of the given dataset.
- Max. number of files for a point lookup: the maximum number / percentage of number of files to lookup. It’s the highest point of y-axis.
- Estimated average num of files for a point lookup: average of number of files to lookup, excluding the range that does not exist.
- Max. bytes to read for a point lookup: the maximum bytes of files to read for a point lookup.
Analysis result on sorted dataset
To understand the result clearly, let us check the result from sorted dataset.
Sample data generation
// Scala
val dataPath = "testDataDir"
val randomDataPath = dataPath + "/randomData"
val sortedDataPath = dataPath + "/sortedData"
spark.range(50000000).map { _ =>
(scala.util.Random.nextInt(10000000).toLong, scala.util.Random.nextInt(1000000000), scala.util.Random.nextInt(2))
}.toDF("colA", "colB", "colC").repartition(100).write.format("parquet").save(randomDataPath)
// 50M rows with random integers stored in 100 parquet files.
val randomDF = spark.read.parquet(randomDataPath)
randomDF.repartitionByRange(100, col("colA")).sortWithinPartitions(col("colA")).write.format("parquet").save(sortedDataPath)
val sortedDF = spark.read.parquet(sortedDataPath)
import com.microsoft.hyperspace.util.MinMaxAnalysisUtil
displayHTML(MinMaxAnalysisUtil.analyze(sortedDF, Seq("colA", "colB"), format = "html")) // format "text" and "html" are available.
// println(MinMaxAnalysisUtil.analyze(sortedDF, Seq("colA", "colB"), format = "text"))
Result analysis
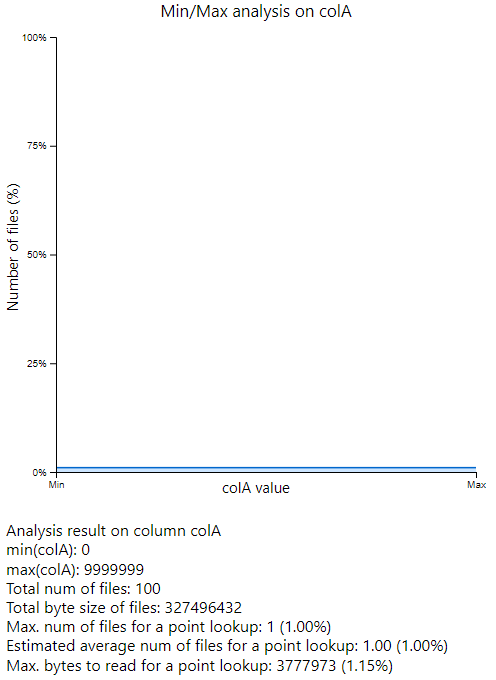
The maximum number of files to be checked is 1 as the dataset is repartition by range of colA.
In other words, we need to check only one file to check if a value exists or not, based on min/max
value of each file. The sorted data layout would be the best performance for colA.
However, for colB, we should read all the files as its randomly distributed:
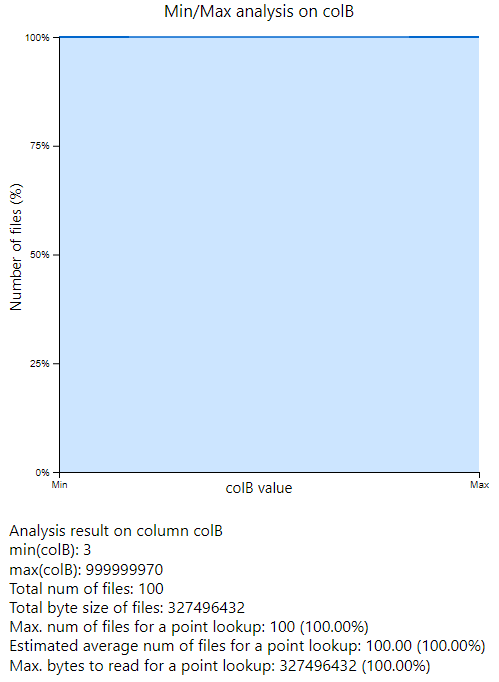
Therefore, with this dataset, we cannot accelerate a query with conditions of colB.
Analyze Z-order covering index data
Index creation & analysis
// Index creation
import com.microsoft.hyperspace.index.zordercovering._
import com.microsoft.hyperspace._
import com.microsoft.hyperspace.util.FileUtils
import org.apache.hadoop.fs.Path
val totalSizeInBytes = FileUtils.getDirectorySize(new Path(randomDataPath))
val sizePerPartition = totalSizeInBytes / 100
spark.conf.set("spark.hyperspace.index.zorder.targetSourceBytesPerPartition", sizePerPartition) // Default: 1G
// Changed per file size for z-order index for demonstration
val df = spark.read.parquet(randomDataPath)
val hs = new Hyperspace(spark)
hs.createIndex(df, ZOrderCoveringIndexConfig("zorderTestIndex", Seq("colA", "colB"), Seq("colC")))
import com.microsoft.hyperspace.util.MinMaxAnalysisUtil
displayHTML(MinMaxAnalysisUtil.analyzeIndex(spark, "zorderTestIndex", "html"))
Result analysis
Compared to sorted dataset, we need to read more files to find a value of colA column.
For example, if we have a query df.filter("colA == 0") which is the minimum value.
Based on min/max value of each file, we should check about 17 files.
It will show worse performance than above sorted dataset that only one file contains the minimum
value.
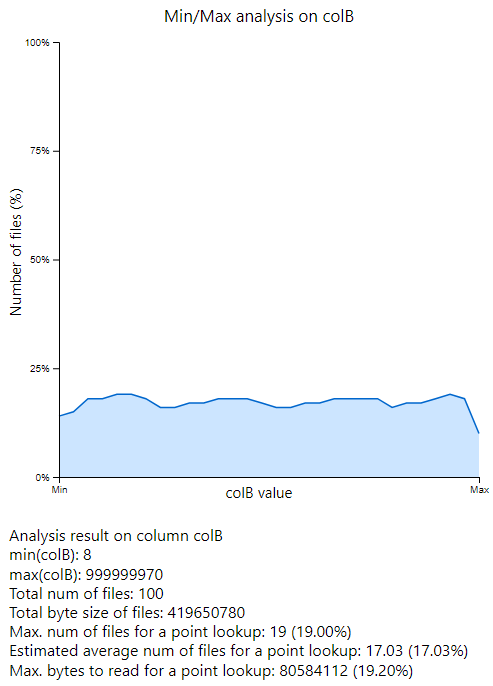
However, we expect better performance for colB as colB values are also considered in the result
ordering. Now we can skip about 80% of files when finding a value of colB in the dataset.
Note
Currently, data skipping for ZOrderCoveringIndex index data relies on statistics and skipping feature in Parquet format itself. Therefore, we need to read the metadata of all files regardless of how many files can be skipped. Accessing each file in a remote storage is not usually cheap, and reading more files also affects spark job scheduling to scan the data. We can optimize it by utilizing data skipping index or maintaining statistics for each index file separately in index log entry, but it is not planned yet.